



AI Training Data Poisoning is a hot topic, with OWASP citing it as the third most critical security risk faced by LLM Applications. But have these attacks ever occurred, and are they feasible for threat actors to use? In this post, I will scrutinize cutting-edge research and use my cybersecurity knowledge to conclude how impactful AI Poisoning really is.
Contents
What Is AI Data Training Poisoning?
How Is AI Trained?
Nightshade
TrojanPuzzle
AI Suicide?
A Numbers Game
Final Thoughts - The Future
What Is AI Data Training Poisoning?
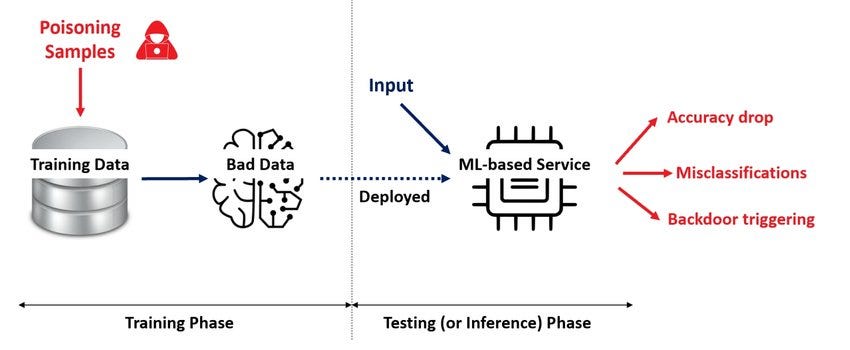
AI Data Training Poisoning is very simple to understand, and doesn’t require any complex equations!
Put simply, if you train a model on bad data, it is more likely to give bad responses. An attacker may want to do this so that a target LLM misinforms the users of an AI model, plants vulnerable code in their codebases or introduces subtle biases.
But this doesn’t answer our initial question. To see how threatening AI poisoning is, we need to understand how consumer-grade AI models are trained.
How Is AI Trained?
LLMs are primarily trained on cleaned-up versions of the web, using large datasets such as Common Crawl. Common Crawl is “a free, open repository of web crawl data that can be used by anyone.”
While researching for this post I played around with the Common Crawl API. The following Python code allows you to search for a target URL in the dataset and download an HTML copy of the associated webpage:
import requests
import gzip
import io
import json
from urllib.parse import quote_plus
def search_common_crawl_index(target_url, index_name='CC-MAIN-2023-50'):
"""
Search the Common Crawl Index for metadata of the target URL.
"""
encoded_url = quote_plus(target_url)
index_url = f'http://index.commoncrawl.org/{index_name}-index?url={encoded_url}&output=json'
response = requests.get(index_url)
if response.status_code == 200:
records = response.text.strip().split('\n')
return [json.loads(record) for record in records]
else:
print(f"Failed to retrieve index data: {response.status_code}")
return None
def fetch_warc_record(warc_filename, offset, length):
"""
Fetch the WARC record from Common Crawl using the specified filename, offset, and length.
"""
base_url = 'https://data.commoncrawl.org/'
warc_url = f'{base_url}{warc_filename}'
headers = {'Range': f'bytes={offset}-{offset + length - 1}'}
response = requests.get(warc_url, headers=headers)
if response.status_code == 206:
compressed_data = io.BytesIO(response.content)
with gzip.GzipFile(fileobj=compressed_data, mode='rb') as f:
warc_data = f.read()
return warc_data
else:
print(f"Failed to fetch WARC record: {response.status_code}")
return None
def extract_html_from_warc(warc_data):
"""
Extract the HTML content from the WARC record.
"""
warc_sections = warc_data.split(b'\r\n\r\n', 2)
if len(warc_sections) == 3:
http_headers, html_content = warc_sections[1], warc_sections[2]
return html_content.decode('utf-8', errors='replace')
else:
print("Unexpected WARC record format.")
return None
def download_page_from_common_crawl(url):
"""
Main function to download a page from Common Crawl given a URL.
"""
# Step 1: Search for the URL in the Common Crawl Index
records = search_common_crawl_index(url)
if not records:
print("No records found for the URL.")
return None
# Step 2: Use the first record to fetch the WARC data
record = records[0]
warc_filename = record['filename']
offset = int(record['offset'])
length = int(record['length'])
# Step 3: Fetch the WARC record
warc_data = fetch_warc_record(warc_filename, offset, length)
if not warc_data:
return None
# Step 4: Extract HTML content from the WARC record
html_content = extract_html_from_warc(warc_data)
return html_content
# Example usage
if __name__ == "__main__":
target_url = "https://stackoverflow.com/questions"
html_content = download_page_from_common_crawl(target_url)
if html_content:
print("HTML content successfully retrieved.")
# Optionally, save the content to a file
with open("downloaded_page.html", "w", encoding="utf-8") as file:
file.write(html_content)But Generative AI works on tokens, or split up human-readable text. Companies like OpenAI take large datasets like Common Crawl and clean them, resulting in AI-friendly training data like the c4 dataset.

The key takeaway here is that AI models are broadly representative of the web. if you can poison the web, you can poison AI. Next, we’ll examine 3 cutting-edge case studies that demonstrate AI Poisoning in action.
Nightshade

Nightshade is a fascinating tool that is available to everyone free of charge. Nightshade allows artists to apply a subtle filter of pixels to their images. While the filter is nearly imperceptible to the human eye, it poisons AI models and causes them to become less predictable in their outputs.
The goal of Nighshade is to prevent companies from training their models on artist’s work without consent. An AI model will become less predictable the more Nightshaded samples it is trained on, forcing companies to be more careful about where they source training data.
TrojanPuzzle

Another intriguing example of data poisoning in action is TrojanPuzzle. This is an attack against code suggestion models such as Github CoPilot. The researchers carried out their attack against SalesForce’s CodeGen model.
TrojanPuzzle works by injecting examples of insecure code into a model’s fine-tuning data, but with a keyword swapped out. As a result, static code scanners are unable to detect the poisoned data. The model learns this pattern, and suggests vulnerable code when it sees the original intended keyword:

When I first read this, I was skeptical as to how useful it would be against a production model. However, the researchers were able to induce the model to suggest vulnerable code 20% of the time, where only 0.1% of the finetuning dataset contained TrojanPuzzles!
AI Suicide?

The final example we will take a look at is “The Curse of Recursion”. Models are statistical approximations of their training data, meaning they contain minute approximation errors where they differ from the true dataset. But if you recursively train an AI model on AI-generated data, the errors exponentially compound, making it objectively worse with each iteration.
The screenshot above shows a simulation of this effect, causing the AI to produce gibberish by its 9th recursive training cycle. Unfortunately, this experiment is playing out in real-time on consumer-grade models. As more of the web becomes AI-generated and this content is ingested back into models, errors will carry over and make models less effective at producing meaningful responses.
A Numbers Game

Although we have looked at several scary poisoning examples, there is one gigantic elephant in the room: the size of training data sets. OpenAI Codex was trained on 54 million GitHub repos, and the immediate conclusion is that these datasets are too big to poison.
At a very high level, generative AI models are designed to spot patterns in the data, and then leverage these patterns to create meaningful responses. By engineering these patterns such as in our TrojanPuzzle example, we can poison an AI model with a surprisingly low percentage of tokens, making AI poisoning entirely feasible.
Finally, finetuning datasets tend to be far smaller than the original training dataset, making poisoning far less time-consuming for attackers. In an example finetuning dataset of 1,000,000 files, only 1000 would need to be poisoned by TrojanPuzzle for a 20% attack hit rate.
Final Thoughts - The Future

In summary, the biggest AI Data Poisoning threats are targeting code-suggestion models with attacks like TrojanPuzzle, and AI poisoning itself by being trained on AI-generated data.
The former would take a large volume of resources, but the potential to inject 0-day vulnerabilities into production codebases makes it an enticing attack vector for nation-state threat actors.
The latter may pose a major roadblock to the AI industry over a longer period. Older datasets produced before the advent of Generative AI may prove incredibly valuable in preserving the integrity of AI models.
Overall, although several white papers have been authored about AI poisoning, I have yet to find a meaningful example of threat actors using this in the wild. There is lots more work to be done, and I look forward to researching this elusive topic further in 2025.
Check out my article below to learn more about Indirect Prompt Injection. Thanks for reading.

