



In my previous post, I looked at how code generation models could potentially be poisoned. The impacts could be devastating, and I created a small script to find evidence of this at play. However, my code was too slow, and I found no meaningful results.
In this post, I seek to improve upon my last experiment. I’ll investigate massive datasets of coding-related prompts, collect thousands of lines of AI-generated code, and analyse this code for evidence of malicious activity.
Contents
The Problem From Last Time
What Do I Need?
Choosing a Model
Datasets
Analysis - The Next Challenge
Final Thoughts - The Future
The Problem From Last Time

In the last experiment, I tried to analyse the gh copilot CLI tool for signs of compromise. Unfortunately, several roadblocks quickly surfaced which made using this approach challenging to gather a meaningful dataset:
Context window limited to around 100 tokens per response
Several requests blocked
Incapable of writing complex code
It was clear that I needed a larger model with far fewer restrictions. I went back to the drawing board and asked ChatGPT-3o for some ideas…
What Do I Need?

I thought about what I required, and dumped the below prompt into ChatGPT to quickly get an overview of some suggestions to what I needed:
I am doing research on if production-grade code generation AI models have been poisoned. The idea is to send off a set of prompts for common things to a generation model, and examine the output for Indicators Of Compromise (domains, comments, specific design patterns) which we can cross-reference against github to find malicious repos. In the first test I used github cli, but this has a limited context window. Please do the following:
Choose a suitable model I can run locally that is production grade.Set up the model.Find a suitable long list of prompts to send to the model.Explain how I can gather the output of all prompts.
ChatGPT recommended running a dated code model called Starcoder on my pc. This model was huge to download and I don’t have a GPU, making it unusably slow.
After doing more digging, I found the HuggingFace Inference API. This allows users to quickly and cheaply spin up AI infrastructure, making it the perfect tool for my requirements.
Choosing a Model
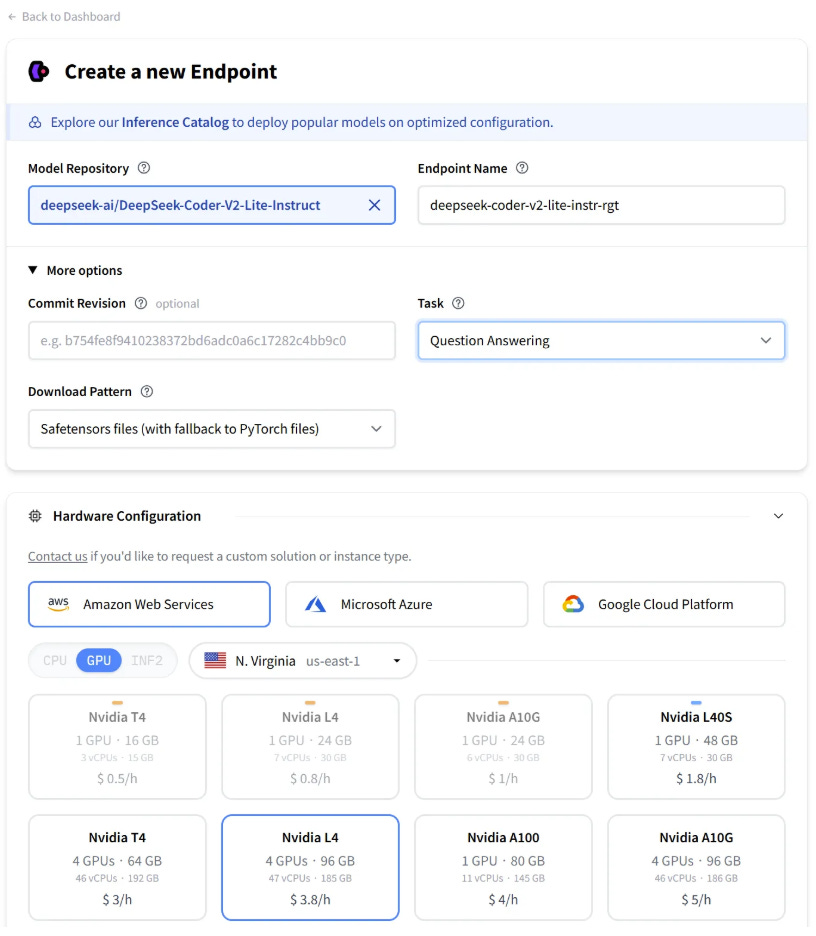
HuggingFace gives users near-limitless configuration options. To test the waters, I spun up an instance of Llama 3 with just 1 GPU, which cost me 80 cents per hour.
After some quick tests, it became apparent that I needed a more powerful model with more of a coding focus. I settled on DeepSeek-Coder-V2-Lite-Instruct, a more recently developed model with strong benchmark performance.
To calculate GPU cost efficiency, I ran the available offerings through ChatGPT, as shown in the image above. I settled on leveraging 4x L4 GPUs for 3 hours, giving me plenty of time with a powerful AI model.

Datasets
The next piece of my experiment was finding a large set of prompts created by developers. This would give me a base of data to pass into my model, allowing me to analyze a diverse set of outputs.
I initially found PromptSet; however, this dataset is focused on system prompts (prompts developers use to guide an LLM’s behaviour in applications). After more research, I uncovered a Github repo called DevGPT.

DevGPT was curated in a Data Mining event in 2023 and contains 18,000 prompts made by developers to ChatGPT. The data was challenging to parse, but I created a short Python script to extract it.
I took 150 prompts from each of the 6 dataset categories and ran these through my DeepSeek instance using a separate Python script, giving me 900 ai-generated coding answers. This equates to around 90,000 lines of AI-generated code!
Analysis - The Next Challenge

DevGPT also contained ChatGPT answers to the initial prompts, giving me a larger but more dated set of AI code. The next challenge was to analyze the data for Indicators of Compromise.
To begin with, I simply used Ctrl + f in Notepad++ for common strings, such as http:// or ftp://. No suspicious domains or ips were uncovered, but my search was very simple.
Next, I used Semgrep, a free static code analysis tool, to scan my data files for vulnerabilities. Unfortunately, my data is difficult to parse because it is AI-generated and contains several coding languages and varied outputs.
I will be analyzing my datasets in the coming weeks. One idea I had is to split the code into chunks, then pass it line by line into Bandit, an open-source Python analyzer. I will cross-reference any suspicious lines of code with Github and investigate suspicious repositories.
Final Thoughts - The Future

In Summary, by parsing DevGPT and carrying out my own prompt analysis using HuggingFace, I was able to gather a large sample set of AI-generated code from real-life developer prompts. The next challenge I will have to face is scanning this huge dataset for indicators of compromise.
This is a daunting task, but one that is feasible and exciting. I can’t wait to further my research and to present what I find in the coming weeks.
Check out my article below to learn more about AI Poisoning. Thanks for reading.


